BitcoinDA
... About 6 min
# Optimistic Rollup with BitcoinDA
This is a high level overview of BitcoinDA and its architecture. If you are looking for more specific documentation or instructions for using BitcoinDA, head to Syscoin's BitcoinDA documentation (opens new window).
The general design for a layer 2 using BitcoinDA on Syscoin layer 1 can be applied with ZK-based rollups (we have prototyped this with Hermez zkEVM) the same as we have applied with Optimism Bedrock. Since optimistic rollups have some advantages over zkEVM right now due to the overhead of ZK proving, we chose to integrate with Bedrock to begin, and will introduce a hybrid solution likely along the lines of Bedrock/Hermez/zkSync upon emergence of hardware-efficient ZK proving solutions. We feel the Bedrock design is currently the cleanest, most secure and efficient of any of the many rollup designs today.
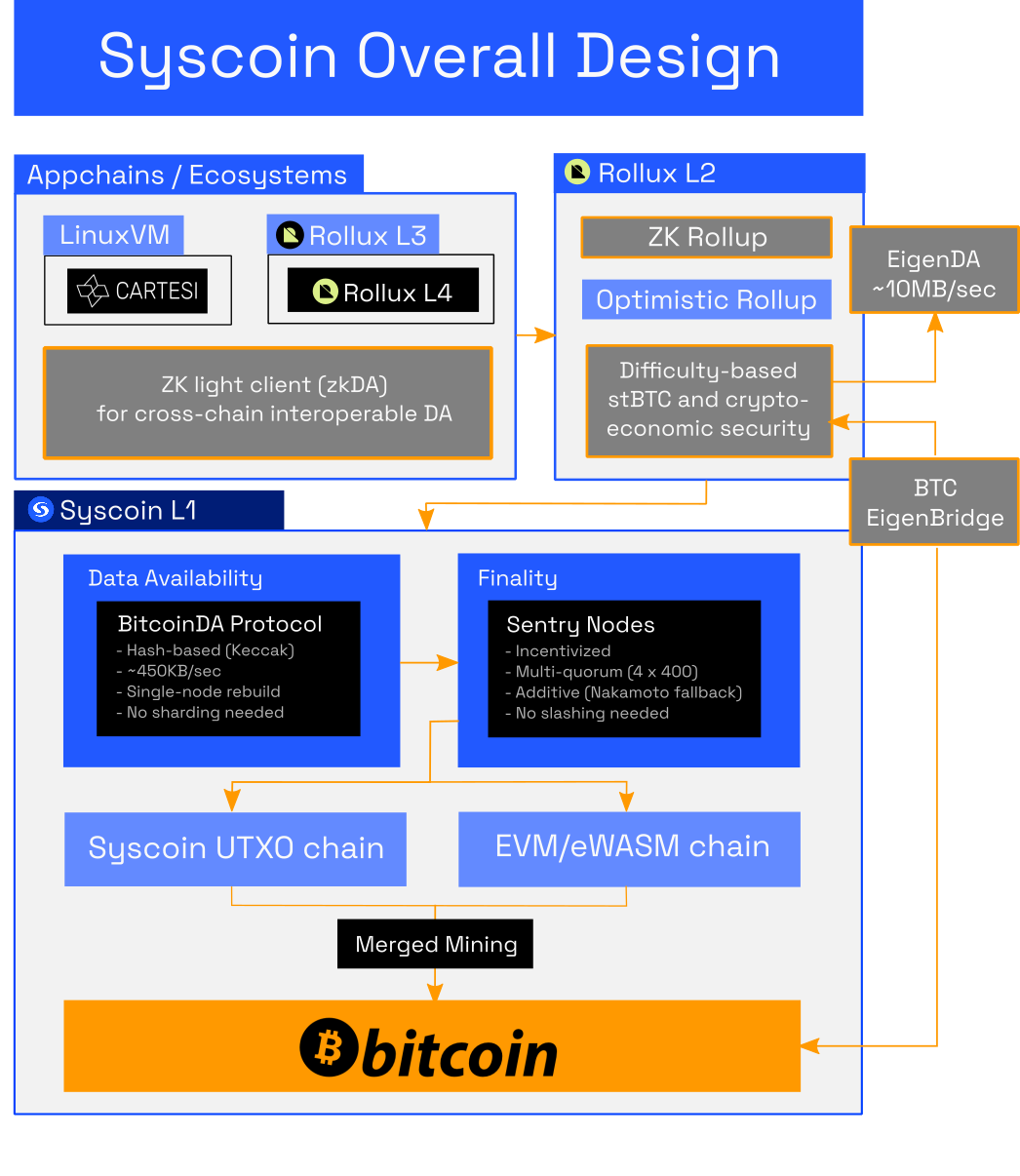
The base layer required a working mechanism for decentralized finality, hash-based blobs and an EVM that is stable and able to provide censorship resistance to rollups on layer 2 and beyond. We released finality + EVM in our NEVM release (Syscoin Core v4.3) in December 2021. To integrate BitcoinDA, we assessed the Bedrock codebase of Optimism and created our initial integration.
You can view the difference between Rollux's and Optimism's approaches to data availability firsthand by viewing this Github commit: https://github.com/sys-labs/rollux/commit/25a4c9410ddae31ff7195f67495491f71e684e03 (opens new window). You can also view the full diff here: https://github.com/ethereum-optimism/optimism/compare/develop...sys-labs:rollux:develop (opens new window).
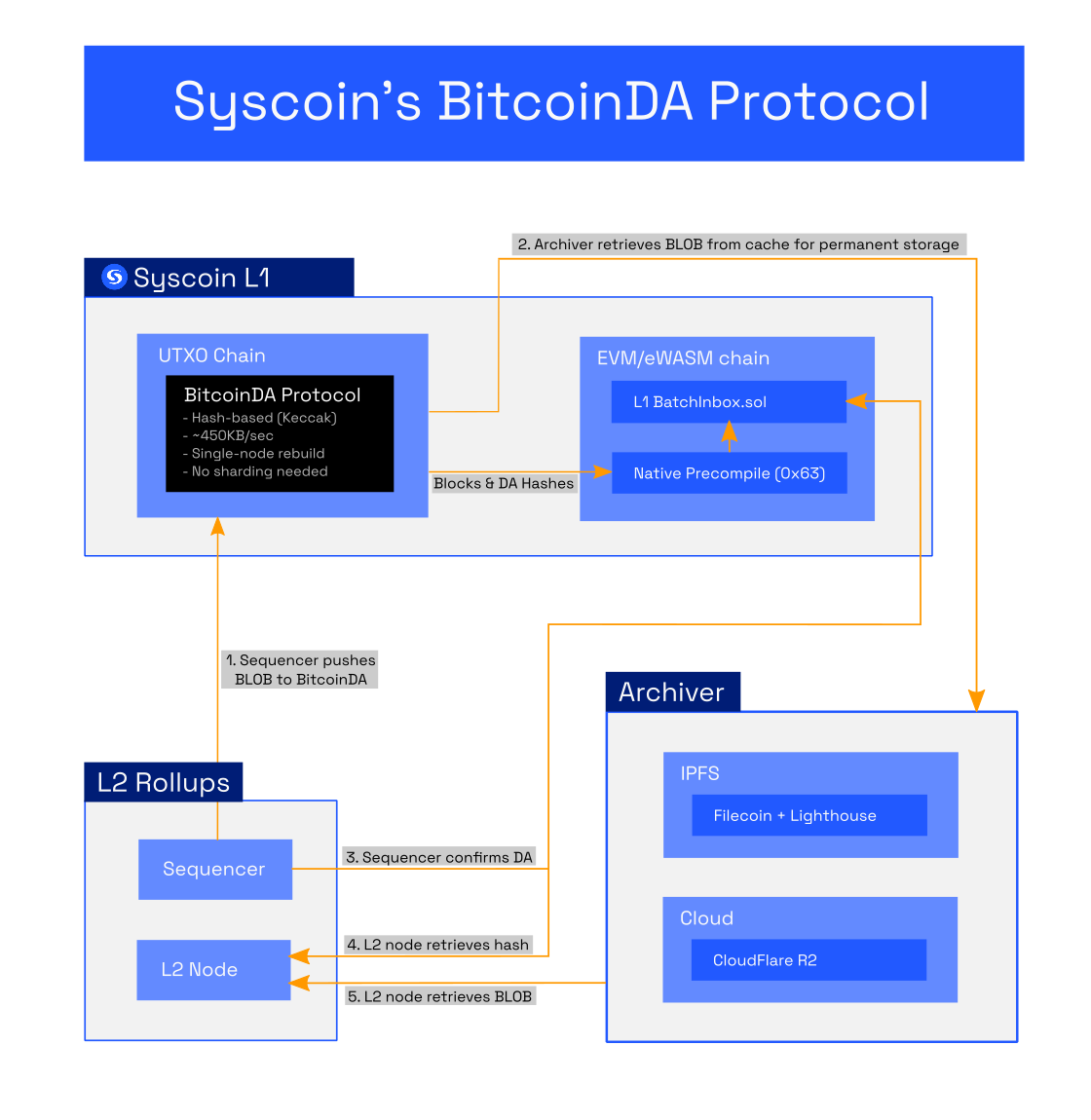
The gist of the integration is summed as follows. This allows us to easily integrate BitcoinDA into any rollup systematically. You can follow the graphic above with the explanation of the numbered sequences below.
The
sequencer(responsible for preserving the order of the unsafe blocks on the rollup, and enabling data availability) sends raw transactions to BitcoinDA (on our UTXO chain) which confirms the blob via its Keccak hash. Data lookup can be performed in the NEVM via a precompile by its Keccak hash. It would create blobs (for now it creates just 1 per L2 block) but theoretically the sequencer can create multiple blobs at once.An ancillary service is running to get the blob data from the UTXO chain to throw it in an
indexer. Anyone can do this, and only one honest person needs to do this for the design to remain censorship resistant. Initially we used Cloudflare R2 which is a distributed database for our first bedrock release. Shortly after we added Filecoin with permanence via Lighthouse for redundant archiving. Any storage providers can be used.Upon confirmation of the blob, the batcher calls a smart contract for data lookup to ensure the blob is available on the network. In Bedrock’s case, we called this
BatchInbox.sol. Simply put, it allows an array of Keccak hashes to be passed in via standard calldata. It loops to check they exist on the network via a precompile. The data availability is now preserved and the hash of the data is stored in the calldata of the call to the smart contract that verifies the data exists. Theoretically since it can process an array of hashes you can process multiple blobs here. Note that the UTXO chain can process up to 32 blobs of 2MB each but if you process more than that you simply need to wait for confirmation for all of the blobs prior to checking for confirmation of the data via BatchInbox.sol.The L2 Node derives the state deterministically via the underlying chain reading the BatchInbox call (filtered by the address of the batcher to ensure its not responding to calls from other addresses). We can fetch the Keccak blob of the hash, check that the contract executed successfully. That means the data existed and was sent by the sequencer at the time of the creation of L2 blocks.
Then we fetch the data from any indexer that has archived it. We run one by default storing the data in the cloud via Cloudflare R2 but we can preserve the data in any way including Filecoin or decentralized stores as well. It can be anybody storing this data and providing it as a service.
Upon receiving the data from an indexer, we rehash it to check that it is consistent with what was given to BatchInbox. We then process it as normal by deserializing the rollup transactions and putting them into rollup blocks.
The underlying mechanics don’t change much from what we called OPv1. Previously the data was stored in the calldata of a transaction on Syscoin NEVM. Now that method is replaced with a contract call to check if the hash exists as a blob. The derivation of data changes from fetching it from the calldata of an EVM transaction, to fetching the hash instead, then looking up the data from an external indexer via that hash.
The simplicity of integration this offers will enable us to integrate other rollup designs fairly easily, including natively plugging-in our Keccak blob mechanism to Hermez zkEVM (a state-of-the-art ZK Rollup design with the Plonky2 prover) and others (zkSync, Scroll.tech, Starknet, once they are open-sourced). Then we can approach our own informed model as we combine Optimistic with ZK in appropriate ways (ie: unsafe blocks secured via fraud proofs, and validity proofs secure the system once the unsafe blocks are stored through BitcoinDA).
BitcoinDA generically allows us to have censorship-resistance of data for rollups. This means censorship-resistance that ensures users can exit the rollup, preserving the security provided by Syscoin’s layer 1. As game-changing as that is in itself, the implications extend further, to other things like storing business rules on a public system for censorship-free permissionless auditing of regulation-compliant EVM rollups and more.
# Architecture of BitcoinDA
We recommend the reader have a good understanding of Syscoin’s basis for secure finality that does not compromise the antifragility properties of Proof-of-Work before proceeding into the architecture of Syscoin's data availability protocol.
BitcoinDA calls for pruning raw data received by nodes processing blocks and leaving just the hash of that data in its place. Ethereum is also doing this with EIP-4844 using KZG commitments. While our general strategies are similar, Syscoin brings several important differences that promote better decentralization, performance, and overall security.
Syscoin uses Keccak-based blobs.
No trusted setup
Quantum safe
Very performant.
Syscoin does not shard data. Every full node processes blobs fully.
Trust yourself only
Fewer attack vectors
Data is simple to reproduce and check
Syscoin can prune data much quicker, and tie in pruning with finality + 6 hours.
# Hash-based Blobs
Why does Ethereum employ a KZG polynomial commitment scheme, rather than using Keccak?
Due to Ethereum's sharding architecture, validators hold only a fraction of the data in segments (similar to how nodes in a traditional distributed database store only a small part of the entire database). Ethereum requires an effective method to verify that these individual segments are valid pieces of the whole and to confirm the data's accuracy. This is important for ZK (validity proof) rollups for which data hashes are fed to the ZK verifier to confirm they are processing state correctly.
Within ZK rollups, it is expensive to check KZG commitments directly. This is due to the number of constraints within the ZK circuit. There is a simple way to check if two totally separate commitments map to the same data input, using the equivalence protocol. Ideally, the commitment scheme should be hash-based to avoid trusted setups and ensure quantum safety. However, most of the hash algorithms used in ZK circuits are new and completely untested in the real world (their security is not proven). Ideally, the commitment scheme should be hash-based to eliminate trusted setups and make it quantum-safe. However, most hash algorithms employed in ZK circuits are novel and untested in real-world scenarios (their security is unproven). It is likely that they would prefer to use the merkle-root SHA256 hash-based scheme, but it is incompatible with the sharding design philosophy! For Ethereum, KZG is the most efficient solution, but it comes with a trusted setup! In contrast, sharding is not a concern for Syscoin, which allows for some substantial benefits.
In addition, this is also much better performance-wise, even considering that Syscoin’s full nodes check the entire set of data at every block for data availability. Syscoin provides up to 64 megabytes per block and up to 32 blobs (2 megabytes each) of space available per block (2.5 minutes on average). The blob size fits nicely within our existing fee-market on Syscoin’s native UTXO chain. We simply discount the weight of the block by 100x. That is to say a full block of 64 megabytes accounts for 640kb, leaving 360kb of effective weight in a 1MB block for regular transactions. The fee-market for blobs is discounted 100x from regular transactions, while the rest of the fee-market logic remains consistent with bitcoin mechanics tried and tested over a number of years. In Ethereum’s alternative sharded setup, 32 blobs of 2 MB each are aggregated in a KZG verification which takes roughly 3 seconds (about 2 seconds for each individual blob), while Syscoin’s Keccak-based blob takes about 1 millisecond to check. That corresponds to 2000x in performance savings (2000ms per blob vs 1ms per blob).
Given the fact that we use a compact block based strategy to disseminate blocks around the network, and that these blobs would have been checked in-between blocks as transactions entering the mempool (cached as a result), when a compact block arrives (only a few kilobytes of data) the resulting blob does not have to be re-checked. This leads to block propagation with minimal overhead and good stability, which is a key metric when dealing with decentralization of a chain. Blocks being slow and steady at a target of 2.5 minutes, gives sufficient time to propagate blobs and verify/cache them for inclusion in a block. The overhead of BitcoinDA is minimal during run-time and maximizes decentralization whilst fulfilling the fully-secure censorship resistance criteria for rollups.
# Pruning in BitcoinDA
The final piece to understand BitcoinDA is how the protocol removes raw data after network participants have had the opportunity to archive it. Upon receipt of a new chainlock (opens new window), the protocol prunes data older than or equal to six hours of age from the time of the previous chainlock. Since the previous chainlock is effectively the guaranteed finality of the chain, we depend upon it for data removal. The age of the data is based on the time difference between the last guaranteed finality, and the median time-stamp of the block that included the data blob.